Key Takeaways From the Blog
- Eliminate Edge-Case Headaches: The Header node gives you a fixed starting point, simplifying insertions, deletions, and traversal.
- Master Five Variants: Singly, doubly, grounded, circular, and circular two-way lists — each with its own use case.
- Apply in Real Systems: Perfect for queues, polynomial operations, memory managers, and OS-level tasks.
- Learn by Doing: Includes a complete C implementation so you can code, debug, and practice.
- Ace Your Interviews: Strengthens pointer logic and reduces bugs in edge cases.
Introduction
You want to write simple and error-free linked list code that works reliably for insertions and deletions without wasting time on tricky conditions. With normal linked lists, you often have to check if the list is empty, handle special cases for the first node, and fix bugs from subtle pointer mistakes.
A Header Linked List solves this by providing a fixed starting point. This guide will show you how this fixed-anchor approach works, explore its five key types, detail its real-world use cases, and give you a full C program to practice with, helping you ace your projects and interviews.
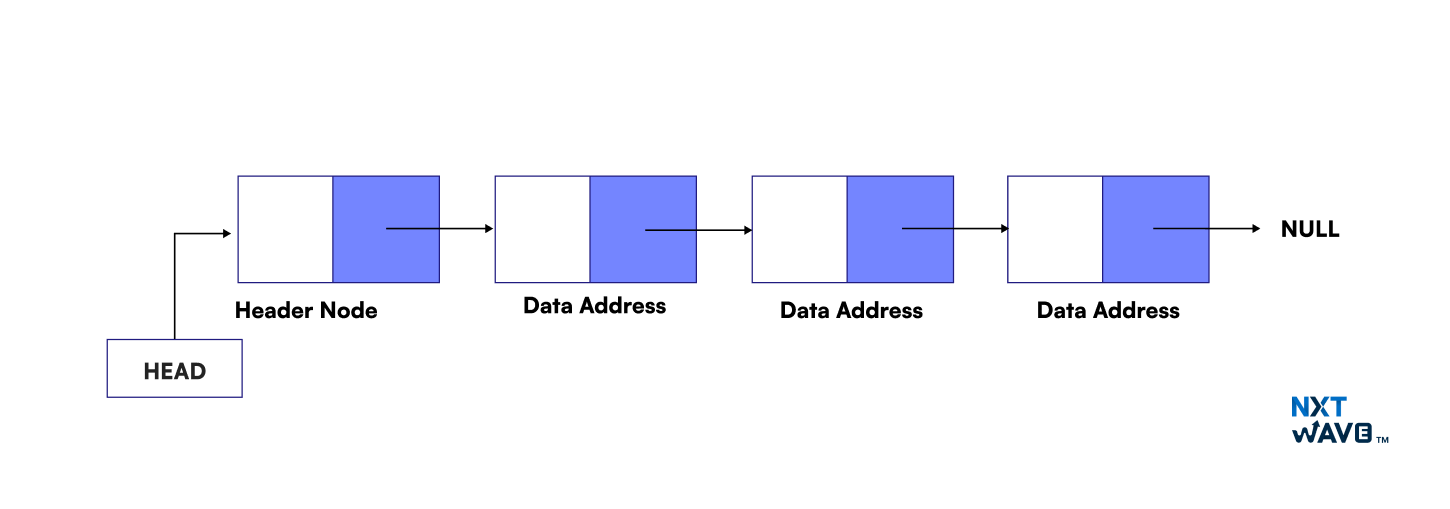
A Header Linked List is a specialized linked list that uses a dummy header node at the very beginning. This special node does not store data but serves as a permanent, fixed reference point for the entire structure.
This structure fundamentally changes how you perform operations:
- Fixed Reference: The header node ensures the list always has a non-null starting point, simplifying insertions, deletions, and traversal.
- Widespread Use: Header nodes are vital in modern systems like compiler symbol tables and memory managers, where predictable and reliable pointer operations are essential for performance.
There are 5 types of header linked lists, namely:
- Singly or Doubly Header Linked List
- Ground Header Circular Linked List
- Circular Header Linked List
- Two-way Linked List
- Two-way Circular Linked List
1. Singly or Doubly Header Linked List
Each node in a linked list, which is a linear data structure, has both data and a reference (or link) to the node after it in the sequence. These nodes are kept in memory. Linked lists can be classified into singly linked lists and doubly linked lists, based on how the nodes are linked to each other.
2. Ground Header Linked List
A grounded header linked list is a linked list where the last node points to null. It is a type of header-linked list with a special node at the beginning, called the header node. The header node allows access to all nodes in the list and does not need to represent the same data type as other nodes.
3. Circular Header Linked List
A circular header linked list is a header-linked list that has a header node at the beginning of the list and the last node points to the header node. This header node is a special node the header node gives access to all the nodes in the linked list.
4. Two-way Linked List
A Two-Way Header Linked List is a variation of the doubly linked list where there is a special header node that serves as an anchor for both directions (forward and backward) of traversal.
5. Circular Two-way Linked List
A Circular Two-Way Header Linked List combines features from both circular lists and doubly linked lists. It has a header node, and both the next and previous pointers of the nodes are used. Additionally, the list is circular, meaning the last node's next pointer links back to the header, and the first node's previous pointer links back to the header as well.
Quick Recap
A Header Linked List uses a dummy start node to simplify all major list operations.
The five primary types are categorized by their links:
- Linear: Includes the basic Singly (forward-only) and Doubly (forward/backward) lists, along with the Grounded type (ending in NULL).
- Cyclic: Includes the Circular list (tail links to header) and the advanced Circular Two-way list (fully looped and bidirectional).
Advantages & Disadvantages of Using Header Linked List
Here are the advantages and disadvantages of using header header-linked list:
Advantages
- The header node provides a permanent reference point, simplifying access to all other nodes.
- Polynomials are usually stored in memory in the form of header linked lists.
- It allocates memory for the actual data nodes, reducing memory waste compared to arrays.
- It is used for storing global information about the list, such as the total number of nodes, minimum value, or maximum value.
Bottom Line:
Header-linked lists trade a little extra memory for code that is more reliable, easier to maintain, and faster to debug.
Disadvantages
- Requires slightly more memory for the dummy node and extra pointers, especially in doubly lists.
- Searching for an element in a Header Linked List can be time-consuming, as it may involve traversing from the start to the point of interest, which is not efficient for large lists.
- It is be difficult to traverse a linked list, and it can take a long time to get to a node.
- It can be challenging to reverse-traverse a linked list.
Here are the applications of the header linked list are listed below:
- It is used for simplifying operations on empty lists as a header node (which is also called dummy node) and used for eliminating the need for special cases when performing operations on empty lists (e.g., insertion, deletion).
- The header node is used to provide a consistent starting point for traversing the list and simplifying iteration even in cases where the list might be empty.
- Mostly used in implementing abstract data types like queues, stacks, or deques where linked lists are used as the underlying storage.
- Header linked lists are commonly used for polynomial operations (such as addition or multiplication) where each term is represented as a node.
- Helpful in dynamic memory management by managing memory blocks efficiently, particularly in systems that use free lists.
- Header nodes are useful in the implementation of memory management systems like garbage collection to track blocks of memory.
Bottom Line:
Header-linked lists are ideal for use cases where frequent updates and safe, repeatable operations are required — from student projects to operating system kernels.
#include <stdio.h>
#include <stdlib.h>
// Definition of the node structure
typedef struct Node {
int data;
struct Node* next;
} Node;
// Definition of the linked list with a header node
typedef struct LinkedList {
Node* header;
} LinkedList;
// Function to create a new node
Node* create_node(int data) {
Node* new_node = (Node*)malloc(sizeof(Node));
if (new_node == NULL) {
printf("Memory allocation failed!\n");
exit(1);
}
new_node->data = data;
new_node->next = NULL;
return new_node;
}
LinkedList* create_list() {
LinkedList* list = (LinkedList*)malloc(sizeof(LinkedList));
if (list == NULL) {
printf("Memory allocation failed!\n");
exit(1);
}
// Creating a header node without any meaningful data (data = -1)
list->header = create_node(-1);
return list;
}
// You add a node to the end of the linked list using this function.
void insert_end(LinkedList* list, int data) {
Node* new_node = create_node(data);
Node* temp = list->header;
// Traverse to the last node
while (temp->next != NULL) {
temp = temp->next;
}
// Insert the new node at the end
temp->next = new_node;
}
// Function to display the list
void display_list(LinkedList* list) {
Node* temp = list->header->next; // Skip the header node
while (temp != NULL) {
printf("%d -> ", temp->data);
temp = temp->next;
}
printf("NULL\n");
}
// Function to delete a node by its value
void delete_node(LinkedList* list, int value) {
Node* temp = list->header;
while (temp->next != NULL && temp->next->data != value) {
temp = temp->next;
}
if (temp->next != NULL) {
Node* to_delete = temp->next;
temp->next = temp->next->next;
free(to_delete);
printf("Node with value %d deleted.\n", value);
} else {
printf("Node with value %d not found.\n", value);
}
}
// Function to free the entire list
void free_list(LinkedList* list) {
Node* temp = list->header;
while (temp != NULL) {
Node* next = temp->next;
free(temp);
temp = next;
}
free(list);
}
int main() {
// Create a new list
LinkedList* list = create_list();
// Insert elements into the list
insert_end(list, 10);
insert_end(list, 30);
insert_end(list, 40);
insert_end(list, 50);
// Display the list
printf("Linked List: ");
display_list(list);
// Delete a node
delete_node(list, 30);
printf("Linked List after deletion: ");
display_list(list);
// Free the list memory
free_list(list);
return 0;
}
Output
The Linked List: 10 -> 30 -> 40 -> 50 -> NULL
Node with value 30 deleted.
The Linked List after deletion: 10 -> 40 -> 50 -> NULL
Explanation
The code uses a Header Linked List to make operations simple and consistent.
The Notes() function immediately sets up a dummy header node (list->header), which acts as a fixed reference point, ensuring the list is never "empty."
- Simple Logic: Operations like insert_end() and delete_node() start traversal from the header. This makes the header a permanent predecessor to the first data node, eliminating complex if statements typically needed when modifying the list's beginning.
- Access: display_list() starts at list->header->next to skip the dummy node.
This approach exchanges minimal memory for cleaner, safer code.
Final Recap and Key Takeaways
- The header node acts as a fixed starting point, removing empty-list edge cases and making insertion, deletion, and traversal much simpler.
- Five types to master: Singly, Doubly, Grounded, Circular, and Circular Two-Way — each designed for specific traversal and system needs.
- Advantages: Cleaner code, predictable operations, metadata storage, and dynamic scalability.
- Applications: Perfect for queues, stacks, memory managers, free-list tracking, polynomial operations, and garbage collection.
- Trade-offs: Slightly more memory usage and O(n) traversal time, but much simpler logic and fewer bugs.
Why It Matters
- Real-World Relevance: Header-linked lists are used in operating systems, compilers, memory allocation systems, and other low-level infrastructure where predictable pointer operations are mission-critical.
- Interview-Ready Concept: Frequently asked in coding interviews to test pointer manipulation, edge-case handling, and debugging ability.
- Future-Proof Learning: Builds a strong foundation for advanced data structures like skip lists, linked hash maps, and custom memory allocators.
Practical Advice
- Code Every Type: Don’t just read — write and test singly, doubly, circular, and two-way versions to build true understanding.
- Visualize Pointer Movement: Draw diagrams for insertions, deletions, and traversals to master memory flow.
- Test Edge Cases: Work with empty lists, multiple deletions, and head/tail insertions until your code never crashes.
- Optimize Your Code: Compare performance with regular linked lists and understand when the header approach saves you complexity.
- Use for Projects: Try implementing a queue, polynomial calculator, or memory manager with header lists to apply your learning.
- Implement from Scratch: Start to code with singly-linked list in C, then extend it to doubly, circular, and two-way versions.
- Trace and Debug: Draw diagrams for each operation (insert, delete, traverse) and trace pointers step by step.
- Break It on Purpose: Test with empty lists, duplicate deletions, and head/tail insertions until your code handles all cases safely.
- Compare Approaches: Build the same logic without a header node and notice how much cleaner the header version is.
- Apply in a Project: Use a header list to build a queue, polynomial solver, or memory tracker — practice makes it stick.
Don't be part of India's 63% Unemployed Grads! Learn Industry-Relevant Skills Now!
Explore ProgramFrequently Asked Questions
1. What is the role of the header node in the linked list?
The header node in the linked list is used to simplify operations such as insertion, deletion, and traversal. It eliminates the need to check for any special cases such as an empty list.
2. Can a header-linked list be useful in a circular or doubly linked list?
Yes, header nodes are useful in circular or doubly linked lists to simplify the traversal and manipulation of the nodes.







.avif)