Database management systems can use several methodologies that ensure data integrity, consistency, and quick failure recovery. One such technique is shadow paging. This way of crashing recovery provides atomicity and durability concerning transaction handling. Shadow paging stands with conventional log-based recovery techniques, including write-ahead logging. Shadow paging minimises large logging activities and guarantees the transaction, if executed, is permits, otherwise completely discarded in case of failure.
This article explores the working of shadow paging in dbms, its advantages, disadvantages, and applications.
What is Shadow Paging?
Shadow paging is an essential recovery technique of database management systems that offers transaction reliability, concurrency, and atomicity. It mainly maintains atomicity and durability in transactions per one of the property sets in ACID properties. Unlike log-based recovery, where each change concerning data is logged in detail, shadow paging sticks to a simpler log-free way. This technique permits database recovery from a failure without data modification.
Upon system failure, all modified pages and the current directory are discarded. In contrast, recovery is brought back up based on the most recent directory as the shadow directory, thus assuring data consistency without requiring complex undo and redo operations.
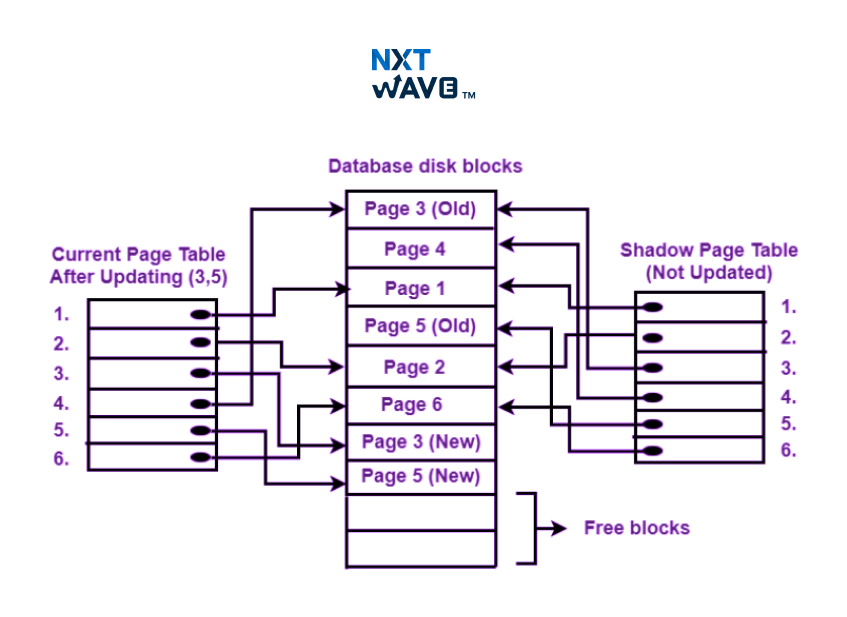
How Shadow Paging Works?
Shadow paging breaks down the database into fixed-size pages, one for which there is an equivalent physical storage address (typically disk blocks). The page table is a structure of data that translates logical pages to their corresponding physical addresses on disk. The steps of the mechanism procedure are:
1. Initial Setup
| Logical Page |
Shadow Page Table (Disk) |
Current Page Table |
| P1 |
Address_1 |
Address_1 |
| P2 |
Address_2 |
Address_2 |
| P3 |
Address_3 |
Address_3 |
- The current page table, which targets actual data pages, is left with pointers in the database.
- Upon beginning any transaction, a shadow page table is created to carry a copy of the current page table.
2. Transaction Execution
| Logical Page |
Shadow Page Table (Disk) |
Current Page Table |
| P1 |
Address_1 |
Address_1 |
| P2 |
Address_2 |
Address_4 (P2') |
| P3 |
Address_3 |
Address_3 |
- Whenever a transaction exceeds a page, a new copy is obtained.
- The shadow page table receives the new page's address while the original page remains unchanged.
3. Commit Phase
| Logical Page |
Shadow Page Table (Disk) |
Current Page Table |
| P1 |
Address_1 |
Address_1 |
| P2 |
Address_4 (P2') |
Address_4 (P2') |
| P3 |
Address_3 |
Address_3 |
- When a transaction has been successfully executed, the shadow page table will take over.
- They become permanent, thus discarding the previous state of the database.
4. Abort or Failure Handling
| Logical Page |
Shadow Page Table (Disk) |
Current Page Table |
| P1 |
Address_1 |
Address_1 |
| P2 |
Address_2 |
Address_2 |
| P3 |
Address_3 |
Address_3 |
- The shadow page table is discarded when a transaction has aborted or failed.
- Current page table remains unchanged, and the database is in the initial state.
Key Concepts of Shadow Paging in DBMS
Shadow paging provides atomicity and consistency by maintaining two copies of each data page:
1. Current Pages: Alterations are stored in recent transactions.
2. Shadow Pages: The previous committed state is stored to roll back when it fails.
3. Page Table: A page table is used to map logical pages to physical pages.
- Before Commit: The references remain associated with shadow pages.
- During Commit: The table is updated to refer to current pages.
- On Failure: The DBMS discards uncommitted changes and maintains consistency.
4. Transaction Log: Keeps all changes, both the original and the shadow pages, in order to allow recovery if failure occurs.
How is Shadow Paging different from Log-Based Recovery?
Here are some key differences between shadow paging and log-based recovery:
| Shadow Paging |
Log-Based Recovery |
| Uses a directory structure for managing fixed-size disk pages. |
Logs every change made to the database. |
| Updates happen to shadow copies; the original stays the same until the commit is achieved. |
Updates proceed in the log, while during the change application, they are limited to whatever is in it. |
| Changes the page directory to take new shadow pages. |
The committing procedure writes a single log entry; much more efficient. |
| The concept is tough to extend for multiple transactions. |
Highly suited to support concurrent transactions. |
| Recovers fast; discarded uncommitted changes. |
Redo and undo procedures are required to maintain consistency. |
| Fragmentation due to the creation of new copies of modified pages. |
Data locality is maintained, thus improving read and write performance. |
Shadow Paging in Different Environments
Here are the shadow paging in different environments such as:
1. Single-User Environment
- In this case, no logs are required since only a single user interacts with the database and thus does not require logs for recovery.
- The changes are applied directly to the database, and recovery can be undertaken simply by reverting to the shadow page after the occurrence.
2. Multi-User Environment
- They are shared by many users at once, a log is needed to control the changes made and also to ensure consistency.
- Shadow paging allows isolated updates; however, another mechanism, such as a lock, is often required.
- Because simultaneous transactions are becoming involved, recovery becomes complex, with logs now managing rollback and consistency.
Failures of Shadow Paging in DBMS
Shadow paging is a fault-tolerant recovery
mechanism in DBMS that maintains data by preserving two separate page tables for committed and uncommitted transactions. Let's see how it addresses the various failures:
1. Transaction Failures
In the event that a transaction fails due to invalid operations, deadlocks, or software crashes, shadow paging guarantees the unaffectedness of the database. Since the work of the transaction is being done on a new set of pages rather than on the original data, an aborted transaction simply gets killed, avoiding the need for an explicit rollback mechanism and thus avoiding inconsistencies.
2. System Failures
Unexpected shutdowns due to power failures or OS crashes may have made the databases unstable. With shadow paging, recovery is much easier because the system will always restart onto the shadow page state. After all, it is stable. The shadow paging mechanism prevents modification of the primary data before the complete transaction commit. Therefore, the DBMS can immediately roll back to the last point without scanning logs or redoing those changes to guarantee the database was consistent.
3. Media Failures
Hardware failures like corruption of a disk drive or crashing of the drive are the real challenges that shadow paging cannot address in their technical sense. While it ensures local consistency, it does not ensure immunity to total data loss. To work on this, a backup solution, replication strategy, or redundancy in cloud storage can relieve an enterprise from complete failure.
Best Use Cases for Shadow Paging in DBMS
The shadow paging is used for following cases:
1. Small to Medium Databases
Medium-sized shadow paging databases that mainly involve read operations and very few updates will benefit from its simpler and more effective recovery mechanism.
2. Read-Intensive Applications
Since reads do not propagate page copying in read-oriented systems, such as data warehouses, reporting systems, and archival databases, shadow paging resolves many read operations versus write operations.
3. Embedded and Lightweight Databases
Shadow paging suits applications with embedded databases, such as mobile devices, IoT systems, and firmware storage. It could be the architecture of choice, given its simplicity and near-instantaneous recovery without the burden of extensive logging.
4. Systems Where Quick Recovery Is Important
Functions requiring the least downtime or rapid failover, such as financial systems, real-time analytics, or mission-critical enterprise applications, might use shadow paging due to its immediate rollback capability.
Advantages of Shadow Paging
Here are the key advantages of shadow paging in DBMS:
1. Reduced Disk Access: Shadow paging has fewer disk accesses than log-based methods, which involve many log writes because it entirely works in terms of page copies and their control.
2. Fast Crash Recovery: Recovery is practically speedy in cases of system failure since uncommitted changes are never merged into the central database for Undo/Redo operations.
3. Good Fault Isolation: Since changes are done on the shadow copy, a failure in one transaction is somehow less damaging to the rest of the database.
4. Higher Concurrency: Since shadow copies allow transactions to change instead of shared data pages, it means more concurrent processing with no conflicts by parallel transactions.
5. Easy to Set Up: Shadow paging is easier to implement, as its log management mechanism is not complex.
6. No Need for Log Files: Unlike log-based recovery methods, shadow paging does not require extensive log files and, thus, comparatively less overhead for storage.
Disadvantages of Shadow Paging
Here are the disadvantages of shadow paging in DBMS:
1. High Commit Overhead: Numerous pages must be flushed in its operation, making the process resource-demanding.
2. Fragmentation of Data: The frequent creation of shadow copies may tend to scatter all related pages across the disk and slow down future reads.
3. Garbage Collection: This requires an extra layer of shadow pages once an obsolete shadow page has been committed and an area of concern.
4. Low scalability for concurrent transactions: Shadow paging provides some concurrency. However, this cannot be adapted to the need for huge environments with many users due to the greater complexity of managing pages.
Conclusion
In conclusion, shadow paging is a crash recovery method that brings atomicity and durability without extensive logging. Certain benefits include fast recovery and ease of transaction management. The trade-offs are found in storage overhead and fragmentation. The algorithm best suits embedded systems, applications with read-heavy workloads, and applications requiring fast recovery. Understanding shadow paging gives a way of choosing the most applicable database recovery mechanism based on system requirements, assuring reliable and efficient database management.
Master Industry-Relevant Skills in College for Your Tech Career Success!
Explore ProgramFrequently Asked Questions
1. What is a shadow page?
A shadow page is a copy of the original database page created during shadow paging. It retains the original, unaltered state of the page throughout the transactions and, thus, ensures data consistency in the event of a failure.
2. What is shadow copy in DBMS?
A shadow copy in a DBMS is effectively similar to that of either the database or a page, but it is one that features the state before an update takes place as a result of any transaction. It is mainly exploited for recovery so that one can revert to the original state if required.
3. What is a shadow database?
A shadow database is often a duplicated copy of the original database for backup, replication, or recovery. This is done to create a shadow of the original database.
4. What is the use of shadow copy?
Shadow copy performs backup and recovery. It helps return the database to its form before failure, thereby retaining data integrity without disrupting ongoing transactions.